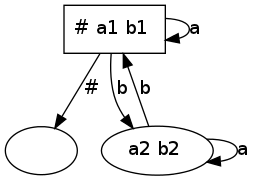
 Voici un autre test avec une expression régulière
caractérisant un nombre pair de b :
Voici un autre test avec une expression régulière
caractérisant un nombre pair de b :
L'idée de départ est la suivante : si un automate fini reconnaît le langage correspondant à l'expression régulière r, alors à toute lettre d'un mot reconnu on peut faire correspondre une occurrence d'une lettre apparaissant dans r. Pour distinguer les différentes occurrences d'une même lettre dans r, on va les indexer par des entiers. Considérons par exemple l'expression régulière (a|b)* a (a|b), qui définit les mots sur l'alphabet {a,b} dont l'avant-dernière lettre est un a. Si on indice les caractères, on obtient
(a1|b1)* a2 (a3|b2)
a1a1b1a1a2b2
L'idée est alors de construire un automate dont les états sont des ensembles de lettres indexées, correspondant aux occurrences qui peuvent être lues à un instant. Ainsi l'état initial contient les premières lettres possibles des mots reconnus. Dans notre exemple, il s'agit de a1,b1,a2. Pour construire les transitions, il suffit de calculer, pour chaque occurrence d'une lettre, l'ensemble des occurrences qui peuvent la suivre. Dans notre exemple, si on vient de lire a1, alors les caractères possibles suivants sont a1,b1,a2 ; si on vient de lire a2, alors ce sont a3,b2.
type ichar = char * int type regexp = | Epsilon | Character of ichar | Union of regexp * regexp | Concat of regexp * regexp | Star of regexpÉcrire une fonction
val null : regexp -> boolqui détermine si epsilon (le mot vide) appartient au langage reconnu par une expression régulière.
module Cset = Set.Make(struct type t = ichar let compare = compare end)
Écrire une fonction
val first : regexp -> Cset.tqui calcule l'ensemble des premières lettres des mots reconnus par une expression régulière. (Il faut se servir de null.)
De même, écrire une fonction
val last : regexp -> Cset.tqui calcule l'ensemble des dernières lettres des mots reconnus.
val follow : ichar -> regexp -> Cset.tqui calcule l'ensemble des lettres qui peuvent suivre une lettre donnée dans l'ensemble des mots reconnus.
On notera que la lettre d appartient à l'ensemble follow c r si et seulement si
Écrire une fonction
val next_state : regexp -> Cset.t -> char -> Cset.tqui calcule l'état résultant d'une transition.
Pour représenter l'automate fini, on se donne le type Caml suivant :
module Cmap = Map.Make(Char)
module Smap = Map.Make(Cset)
type state = Cset.t
type autom = {
start : state;
trans : state Cmap.t Smap.t
}
On peut choisir de représenter ainsi le caractère # :
let eof = ('#', -1)
Écrire une fonction
val make_dfa : regexp -> automqui construit l'automate correspondant à une expression régulière. L'idée est de construire les états par nécessité, en partant de l'état initial. On pourra par exemple adopter l'approche suivante :
let make_dfa r =
let r = Concat (r, Character eof) in
(* transitions en cours de construction *)
let trans = ref Smap.empty in
let rec transitions q =
(* la fonction transitions construit toutes les transitions de l'état q,
si c'est la première fois que q est visité *)
...
in
let q0 = first r in
transitions q0;
{ start = q0; trans = !trans }
Note : il est bien entendu possible de construire au final un automate dont les états ne sont pas des ensembles mais, par exemple, des entiers, pour plus d'efficacité dans l'exécution de l'automate. Cela pourrait d'ailleurs être fait pendant la construction, ou a posteriori. Mais ce n'est pas ce qui nous intéresse ici.
let fprint_state fmt q =
Cset.iter (fun (c,i) ->
if c = '#' then Format.fprintf fmt "# " else Format.fprintf fmt "%c%i " c i) q
let fprint_transition fmt q c q' =
Format.fprintf fmt "\"%a\" -> \"%a\" [label=\"%c\"];@\n"
fprint_state q
fprint_state q'
c
let fprint_autom fmt a =
Format.fprintf fmt "digraph A {@\n";
Format.fprintf fmt " @[\"%a\" [ shape = \"rect\"];@\n" fprint_state a.start;
Smap.iter
(fun q t -> Cmap.iter (fun c q' -> fprint_transition fmt q c q') t)
a.trans;
Format.fprintf fmt "@]@\n}@."
let save_autom file a =
let ch = open_out file in
Format.fprintf (Format.formatter_of_out_channel ch) "%a" fprint_autom a;
close_out ch
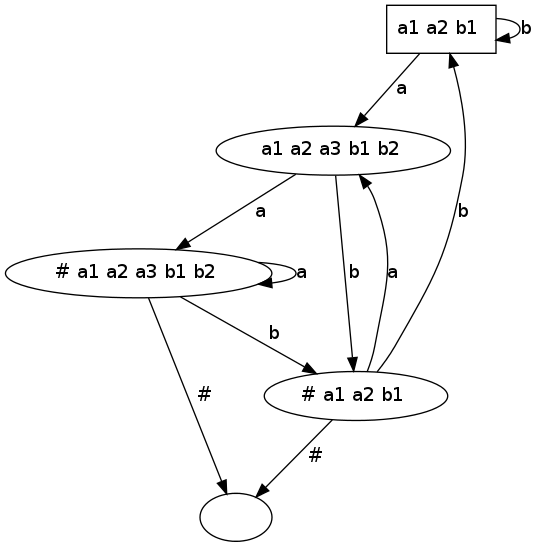 Pour tester, on reprend l'exemple ci-dessus :
Pour tester, on reprend l'exemple ci-dessus :
(* (a|b)*a(a|b) *)
let r = Concat (Star (Union (Character ('a', 1), Character ('b', 1))),
Concat (Character ('a', 2),
Union (Character ('a', 3), Character ('b', 2))))
let a = make_dfa r
let () = save_autom "autom.dot" a
L'exécution produit un fichier autom.dot qui peut être ensuite visualisé avec la commande Unix
dotty autom.dotou encore avec la commande
dot -Tps autom.dot | gv -On doit obtenir quelque chose comme la figure de droite.
val recognize : autom -> string -> boolqui détermine si un mot est reconnu par un automate.
Voici quelques tests positifs :
let () = assert (recognize a "aa") let () = assert (recognize a "ab") let () = assert (recognize a "abababaab") let () = assert (recognize a "babababab") let () = assert (recognize a (String.make 1000 'b' ^ "ab"))et quelques tests négatifs :
let () = assert (not (recognize a "")) let () = assert (not (recognize a "a")) let () = assert (not (recognize a "b")) let () = assert (not (recognize a "ba")) let () = assert (not (recognize a "aba")) let () = assert (not (recognize a "abababaaba"))
Voici un autre test avec une expression régulière
caractérisant un nombre pair de b :
let r = Star (Union (Star (Character ('a', 1)),
Concat (Character ('b', 1),
Concat (Star (Character ('a',2)),
Character ('b', 2)))))
let a = make_dfa r
let () = save_autom "autom2.dot" a
Quelques tests positifs :
let () = assert (recognize a "") let () = assert (recognize a "bb") let () = assert (recognize a "aaa") let () = assert (recognize a "aaabbaaababaaa") let () = assert (recognize a "bbbbbbbbbbbbbb") let () = assert (recognize a "bbbbabbbbabbbabbb")et quelques tests négatifs :
let () = assert (not (recognize a "b")) let () = assert (not (recognize a "ba")) let () = assert (not (recognize a "ab")) let () = assert (not (recognize a "aaabbaaaaabaaa")) let () = assert (not (recognize a "bbbbbbbbbbbbb")) let () = assert (not (recognize a "bbbbabbbbabbbabbbb"))
Plus précisément, on va produire un code de la forme suivante :
type buffer = { text: string; mutable current: int; mutable last: int }
let next_char b =
if b.current = String.length b.text then raise End_of_file;
let c = b.text.[b.current] in
b.current <- b.current + 1;
c
let rec state1 b =
...
and state2 b =
...
and state3 b =
...
Le type buffer contient la chaîne à analyser
(champ text), la position du prochain caractère à examiner
(champ current) et la position suivant le dernier lexème
reconnu (champ last). La fonction next_char renvoie
le prochain caractère à analyser et incrémente le
champ current. Si la fin de la chaîne est atteinte, elle
lève l'exception End_of_file.
À chaque état de l'automate correspond une fonction statei avec un argument b de type buffer. Cette fonction réalise le travail suivant :
Écrire une fonction
val generate: string -> autom -> unitqui prend en arguments le nom d'un fichier et un automate et produit dans ce fichier le code OCaml correspondant à cet automate, selon la forme ci-dessus. Indications :
let start = state42correspondant à l'état initial de l'automate.
Pour tester, écrire (dans un autre fichier lexer.ml, cette fois écrit à la main) un programme qui découpe une chaîne de caractères en lexèmes en utilisant le code produit automatiquement (en fixant le nom du fichier, par exemple a.ml). Le principe est une boucle qui effectue les actions suivantes :
On pourra tester par exemple avec l'expression régulière (a|b)*b des mots qui se terminent par la lettre b, en exécutant
let r3 = Concat (Star (Character ('a', 1)), Character ('b', 1))
let a = make_dfa r3
let () = generate "a.ml" a
puis en liant le code produit avec le fichier lexer.m :
% ocamlopt a.ml lexer.mlSur la chaîne abbaaab, l'analyse doit produire trois lexèmes et réussir :
--> "ab" --> "b" --> "aaab"Sur la chaîne aba, l'analyse doit produire un premier lexème puis échouer :
--> "ab" exception End_of_fileEnfin, sur la chaîne aac, l'analyse doit échouer sur une erreur lexicale :
exception Failure("lexical error")
On pourra aussi tester avec l'expression
régulière (b|espilon)(ab)*(a|epsilon) des mots
alternant les lettres a et b.